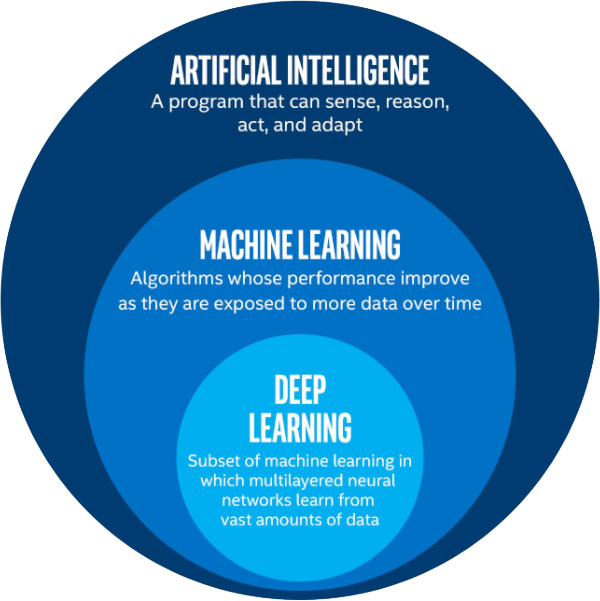
Artificial intelligence, machine learning, and deep learning are interconnected fields, machine learning and deep learning aids artificial intelligence by providing a set of algorithms and neural networks to solve the document problems. However, AI is not restricted to only machine learning and deep learning it covers a vast domain of fields.
AI is a broad branch of computer science; the goal of AI is to create systems that can function intelligently and independently like humans.
Humans can speak and listen to communicate through language. This is the field of speech recognition. Much of speech recognition is statistically based hence, it is called statistical learning.
- Humans can write and read text in a language, this is a field of NLP or natural language processing.
- Humans can see with their eyes and process what they see, this is a field of computer vision. Computer vision falls under the symbolic way for computers to process information.
- Humans recognize the scene around them through their eyes which create images of that world, this field of image processing which even though is not directly related to AI is required for computer vision.
- Humans can understand their environment and move around fluidly, this is a field of robotics.
- Humans have the ability to see patterns such as grouping of like objects, this is the field of pattern recognition. Machines are even better at pattern recognition because they can use more data and dimensions of data.
AI is Changing the way the world works, making business faster smarter and more secure. At IPEX, we're helping companies put AI to work at scale, giving them an unparalleled business advantage.
 Read more
Read more